Design Ideas
This page is a 'white board' for design ideas for the Analysis EnvironmentExecution Engine
The work is done by 'pulling' data from 'Leaf nodes' (i.e. modules whose output does not go to other modules). The pull model allows us to cache the results from an invocation of a module so that next time the module is called we can access the cache. [NOTE: could do this dynamically by watching how long it takes for a module to do its job and if it is above some threshold we try to cache its values?] I now think this is a bad idea, see execution model Modules- take as inputs 'callbacks' to other nodes
- provide as outputs 'callbacks' which can be used to request data
- are configuration options also inputs so they can be manipulated?
- return data
- return a signal
- throw an exception when a problem occurs
- E.g. a module who finds the track with the largest momentum in a container would wait until the 'end of container' signal before sending its value
- E.g. a module who finds the track with the largest momentum in a run would wait until the 'end of the run' signal before sending its value
Execution Model
- Initialize
- mark all nodes as 'off'
- starting from the nodes which were changed since last running
- mark that node as 'on'
- go to all nodes which depend on this one and mark them as 'on' (do this recursively)
- starting from the nodes which were changed since last running
- head up the node chain turning 'on' nodes above recursively until you reach a 'source' (NOTE: cached data for a module would be considered a source)
- add to list of sources
- head up the node chain turning 'on' nodes above recursively until you reach a 'source' (NOTE: cached data for a module would be considered a source)
- Run
- starting from the source, send the appropriate signal/data, calling the 'on' modules connected to that module do this recursively
Example
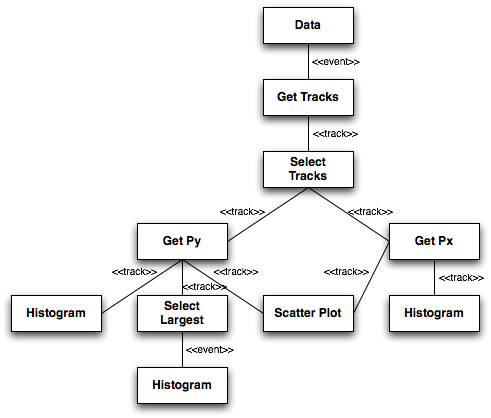
- example execution graph:

- the x momentum of all selected tracks
- the y momentum of all selected tracks
- the largest y momentum for any selected track in an event
- a scatter plot showing the correlation between the x and y components of momentum for all selected tracks
Scenario 1: Starting Fresh
If this is the first time, then all modules will have been turned on. Then the following runtime occurs- The system sends a Begin Query signal to all the nodes
- The
Datanode is the only source and it generates an Event and passes it toGet Tracks. - Since
Get Tracksworks at a finer grain then Event it passes a Begin Event signal to all of its descendents- The
Select Largestcares about Begin Event and resets its internally held largest value
- The
-
Get Tracksextracts the Tracking information from the Event and then starts streaming each individual track to the descendent nodes-
Select Trackslooks at each track sent to it and if the track passes some selection (say minimal chi square) that track is passed down, else it waits for the next message fromGet Tracks -
Get PxandGet Pyonly see the selected tracks and each of these modules sends to its descendents either the Px or the Py value -
Select Largesttakes the Py value and compares it with its present value, if larger it keeps the new value but does not yet send it to its descendents -
Scatter Plotholds the Py value and waits for the Px value before storing its information for the plot
-
-
Get Tracksfinishes sending all the tracks and then sends an End Event signal to all of its descendents- The
Select Largestsees the End Event signal and then sends its presently held value to its descendents
- The
- The
- Once all the events have been processed, the system sends a End Query to all the nodes
Scenario 2: Changing Px histogram
Say you did not like the binning done in the Px histogram and therefore change it- For the initialization, the Px histogram will be turned on as well as the
Get Px. Lets assume the output ofGet Pxwas cached by the system, if so then we only have those two modules turned on - For running, the system sends a Begin Query signal to the two nodes
- Since
Get Pxis now a source, it sends the Begin Event signal (which is ignored)-
Get Pxthen begins streaming its Px value to the histogram
-
- Once done will all the values for that event,
Get Pxsends an End Event signal
- Since
- Once all values are completed, the system sends the End Query signal
Scenario 3: Changing Scatter Plot
Say you did not like the min and max axes values for the Scatter Plot and therefore change it- For the initialization, the
Scatter Plotwill be turned on as well as theGet PxandGet Py. Lets assume the output ofGet PxandGet Pywas cached by the system, if so then we only have those three modules turned on - For running, the system sends a Begin Query signal to the two nodes
- Since
Get PxandGet Pyare now a sources, they sends the Begin Event signal which the system makes sure are the same for each [i.e. the system synchronizes both sources]-
Get Pxthen begins streaming its Px value in synch withGet Pystreaming its Py value
-
- Once done will all the values for that event,
Get PxandGet Pysend an End Event signal (only one signal is sent, not two)
- Since
- Once all values are completed, the system sends the End Query signal
Bread crumbs and Context
As we get more and more specific information, the system keeps track of exactly where the data came from. So for the above example, the system knows the 'Py' information came from Track x which came from Event y. Essentially it leaves 'bread crumbs' for exactly where that piece of information came from. These 'bread crumbs' can be used later to correlate data. This can also let us get access to related data further down the processing train. For example, say we have a track and we want to know which (if any) electromagnetic shower it possibly generated. Since we have both the Track and the Event, we can get from the Event the Association object which given a Track will give back an Electromagnetic shower to which it is matched. Essentially we need to carry around the full Context of the data (e.g. the Event from which the Track came) in order to fully understand the data and its relationships. I now think the Context is a bad idea. The Context would adversely effect a caching system. This is because we would not know what data an active module actually used and therefore we'd have to store the Context and regenerate it for each query. In addition, the Context is really for the case where we do not know what a module may want so we hand it a 'bag of goo' from which it can get anything. In this system we want to track exactly what is used so we can properly provenance track.comparing breadcrumbs
How can you tell if two breadcrumbs are 'synchronized' (that is they are both up to date with respect to the present processing)? Breadcrumbs contain two parts- trail: this is a list with one entry per 'depth' of the breadcrumb [a new depth occurs each time you enter a new container]. An entry is a list of all data accesses that were done at that depth
- indicies : this is a list with one entry per 'depth'. The entry is the key into the container that describes which element of the container you are presently streaming. The key is usually just an integer. In addition, for each entry we also have a flag saying whether this entry is presently valid. This validity flag is used to help synchronize multiple sources in a workflow.
Signal Hierarchy
Signals are used to show a change of Context. The signal will contain- the data object which was changed
- whether this is a 'begin' 'end' or 'instantaneous' signal
- how far up the present 'stack' this signal was produced
Signals generated by a generator module
A generator module takes an input and produces a stream of output based on that one input. When a generator module sees its input, it transforms that input signal into a 'begin' signal and increments the 'stack' value and then sends that signal to all of its children modules. It then sends its output as an 'instantaneous' signal with the stack depth set to 0.Use of Signals by streaming modules
A module which takes an input and can produce an output strictly based on that one input is a streaming module. How does the streaming module know which signal it should react to? It only needs to react to the signal which is labeled as 'instantaneous'.Use of Signals by an accumulating module
A module which waits to see multiple inputs before producing an output is an accumulating module. The accumulating module reads the incoming 'instantaneous' signal and uses it for its accumulation. When an 'end' signal with the appropriate stack depth arrives, the module will send a new instantaneous signal containing its result and with a stack depth of 0. Other 'begin' and 'end' signals received by the accumulating module will be sent to the children but with their stack depths decremented.Sources
Revised #3 Sources are the starting point of the execution of a query. Multiple sources are allowed in a graph but they must agree on how to synchronize. In the case of multiple sources, one of the sources is the active one (i.e. it decides all the transitions which should happen) while all the others are either passive or dependent. A dependent source's breadcrumbs are a proper subset of the active source's breadcrumbs while the passive source's breadcrumbs are not. The synchronization occurs by having the active source invalidate the indicies for its old breadcrumbs, create a new breadcrumb and send its signal which the execution engine then passes the signal's breadcrumbs to all the passive sources [NOTE: could this be done by just having the passive sources take as input the active source's signal?]. The passive sources then use the active source's breadcrumbs to decide if their data must be updated, if it does not then they do nothing, but if it does then they must invalidate the proper indicies of their breadcrumbs. Then all the passive sources are told to send their signals then the active source's signal will be propagated to the proper modules. Running the 'independent' passive sources before the active one and then running the 'dependent' passive sources should minimize any stalling of the processing pipe (stalling can happen when one module needs inputs from multiple sources). Dependent sources must be in the execution graph in their proper place so that they get the appropriate signal (i.e. the signal with the depth one less than they send). Only this way can two dependent source's who share the a proper subset of each other's breadcrumbs will be properly synchronized during the execution. -- ChrisDJones - 24 Aug 2006

| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
ExecutionModelExample.png | manage | 26 K | 27 Aug 2006 - 11:37 | UnknownUser | example execution graph |
{kind=link}
{kind=link}
This topic: HEP/SWIG > WebHome > AnalyisEnvironment > AEDesignIdeas
Topic revision: 13 Sep 2006, ChrisDJones
Topic revision: 13 Sep 2006, ChrisDJones
Ideas, requests, problems regarding CLASSE Wiki? Send feedback