|
|
You are here: CLASSE Wiki>HEP/SWIG Web>EnergyFrontierAnalysisWorkflow>EnergyFrontierViewsOfWorkflow (07 Nov 2007, AndrewDolgert)Edit Attach
Here are two views of the Energy Frontier workflow. The first is through file parentage, the second a picture of the ecosystem of the physicist.
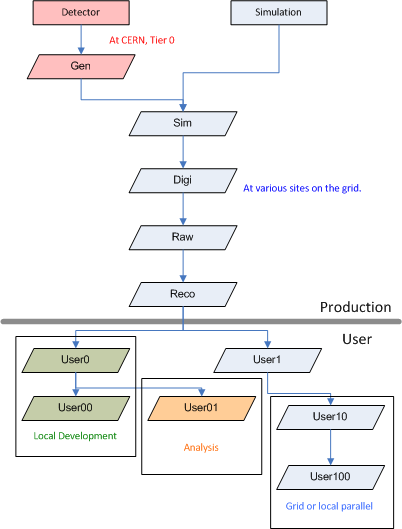 Production is outside of scope. I'm sure the categories at the top are wrong. This is done on purpose to distract Dan from more scathing criticisms. The levels of production are well-defined and explicit, specifying which institutions do calculations, providing software to do each step, and giving the social rules for who gets to decide what is done.
The user work is broken into four categories:
Production is outside of scope. I'm sure the categories at the top are wrong. This is done on purpose to distract Dan from more scathing criticisms. The levels of production are well-defined and explicit, specifying which institutions do calculations, providing software to do each step, and giving the social rules for who gets to decide what is done.
The user work is broken into four categories:
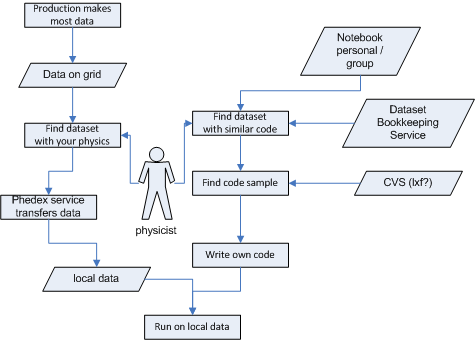 A lot of these steps require physicist input. Finding a dataset starts with Valentin's CMS DBS web page, as does finding code that produced a similar dataset as an example.
There seems to be a lot to remember to do this work. Maybe the physicist needs both workflow tools to get work done and a digital notebook.
A lot of these steps require physicist input. Finding a dataset starts with Valentin's CMS DBS web page, as does finding code that produced a similar dataset as an example.
There seems to be a lot to remember to do this work. Maybe the physicist needs both workflow tools to get work done and a digital notebook.
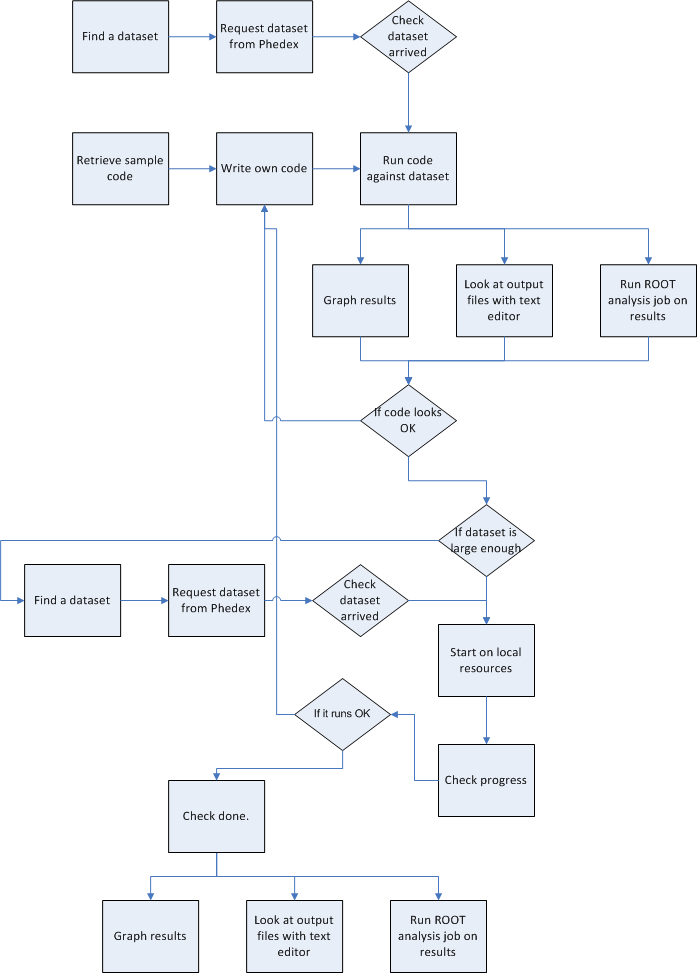 Already we see some repeated patterns, such as moving files around and the various options about how analysis is done.
The first round of running the code could be done on a single processor. The next set of boxes for running code would be more intensive, parallel on a single machine or running distributed on several local machines. It could be that the second step is straight to the grid, meaning grid tools which give access to physically-local resources if not at another institution.
The input datasets come from remote repositories at places like CERN. The program Phedex handles the transfer so that it is optimized over Internet2, TeraGrid, or whatever. It puts datasets into areas in the local filesystem designated by a system administrator. Expect this to be available to all physicists in the group so that people don't copy these very large files after they arrive. When a job starts, it probably reads data straight from this local store. (?) Then the results files could be written to a single network drive or could be written to local drives and collected afterwards.
Streaming isn't interesting for the main processing. It's interesting for the parts of the analysis done after the main cmsrun or ROOT job is over. Streaming work could take over some of the tasks currently assigned to ROOT, like counting events, binning them, and visualization. This is highly parallelizable work.
-- AndrewDolgert - 07 Nov 2007
Already we see some repeated patterns, such as moving files around and the various options about how analysis is done.
The first round of running the code could be done on a single processor. The next set of boxes for running code would be more intensive, parallel on a single machine or running distributed on several local machines. It could be that the second step is straight to the grid, meaning grid tools which give access to physically-local resources if not at another institution.
The input datasets come from remote repositories at places like CERN. The program Phedex handles the transfer so that it is optimized over Internet2, TeraGrid, or whatever. It puts datasets into areas in the local filesystem designated by a system administrator. Expect this to be available to all physicists in the group so that people don't copy these very large files after they arrive. When a job starts, it probably reads data straight from this local store. (?) Then the results files could be written to a single network drive or could be written to local drives and collected afterwards.
Streaming isn't interesting for the main processing. It's interesting for the parts of the analysis done after the main cmsrun or ROOT job is over. Streaming work could take over some of the tasks currently assigned to ROOT, like counting events, binning them, and visualization. This is highly parallelizable work.
-- AndrewDolgert - 07 Nov 2007
Parentage View
I've made several lists and graphs of file parentage in CMS, so it is a natural way for me to think of what a physicist does in this experiment. The file parentage gives a good sense of what is outside the scope of our workflow discussion. It points to several key areas which are inside the scope and are interesting. (These are Visio diagrams. You can replace them with neato-keen Mac versions or we can find some tool I can at least run in Linux.)
Production is outside of scope. I'm sure the categories at the top are wrong. This is done on purpose to distract Dan from more scathing criticisms. The levels of production are well-defined and explicit, specifying which institutions do calculations, providing software to do each step, and giving the social rules for who gets to decide what is done.
The user work is broken into four categories:
- Local Development which means compiling and running against smaller datafiles on a machine where you can login. The machine may be remote from your desk, but much of the work is done interactively in less than a few hours a sitting.
- Grid Submission There are three or four grid software stacks in the great wide world that are used by CMS. What CMS did was write a layer on top of those to abstract them for job submission, which is smart, but it also might hide how grid workflow tools could improve the user experience. That means the work to do grid submission is done but might become in scope if we had a good idea.
- Analysis This is wide open. It refers to all of the stuff that one does to analyze the results of jobs. Some of this is done under the CMS tools, meaning ROOT and cmsrun. Some of it is not. It's worth going into much more detail about this. Chris Jones is working on a streaming tool that would address some of this work.
- Local Parallel I add this as another category because somebody brought it up in the last meeting. The point is that, instead of just running toy calculations at your desk or full-on grid submissions, people now have significant resources in the room, and this is also wide, wide open for workflow tools. Calculations like this would now be done with small job schedulers or by hand.
Environment View
Another way to think about the problem is to ask not what calculations are done but what knowledge is necessary for each step, whether the actor is a person or a program. I have a dumb little graphic for this, but it might help fill in what we must record about work that has been done. I'm not sure how to figure out, with any reliability, which pieces of a workflow get replayed and which don't, but this is where I would start to look.
A lot of these steps require physicist input. Finding a dataset starts with Valentin's CMS DBS web page, as does finding code that produced a similar dataset as an example.
There seems to be a lot to remember to do this work. Maybe the physicist needs both workflow tools to get work done and a digital notebook.
Workflow Attempt
The problem with the previous view of the environment is that I mixed where information comes from with what the basic tasks are. Workflow is about a series of tasks, and then we can fill in the length they take, the data transfered, and all of that.
Already we see some repeated patterns, such as moving files around and the various options about how analysis is done.
The first round of running the code could be done on a single processor. The next set of boxes for running code would be more intensive, parallel on a single machine or running distributed on several local machines. It could be that the second step is straight to the grid, meaning grid tools which give access to physically-local resources if not at another institution.
The input datasets come from remote repositories at places like CERN. The program Phedex handles the transfer so that it is optimized over Internet2, TeraGrid, or whatever. It puts datasets into areas in the local filesystem designated by a system administrator. Expect this to be available to all physicists in the group so that people don't copy these very large files after they arrive. When a job starts, it probably reads data straight from this local store. (?) Then the results files could be written to a single network drive or could be written to local drives and collected afterwards.
Streaming isn't interesting for the main processing. It's interesting for the parts of the analysis done after the main cmsrun or ROOT job is over. Streaming work could take over some of the tasks currently assigned to ROOT, like counting events, binning them, and visualization. This is highly parallelizable work.
-- AndrewDolgert - 07 Nov 2007 {kind=link}
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r1 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r1 - 07 Nov 2007, AndrewDolgert
Ideas, requests, problems regarding CLASSE Wiki? Send feedback