|
|
You are here: CLASSE Wiki>HEP/SWIG Web>CmsDbs>DbsRequirements>DbsUseCases>DbsCsa06UseCases (22 Jul 2006, AndrewDolgert)Edit Attach
CSA06 Use Cases
Contents
- CSA06 Use Cases
- Description of CSA06
- Actor-Goal List
- Usage Narratives
- Physicist Tier 2 Creates Skim of Re-RECO at Tier 1
- Physicist Tier 2 Discovers Tier 1 Data Available for Processing
- Physicist Tier 2 runs analysis job
- Alignment Person Recalibrates using Z to mu-mu to produce a new version of alignment
- Production Manager Tier 2 Re-runs RECO analysis
- Production Manager Watches CSA06 Progress
- Production Manager Creates Real HLT Data from MC Data
- Tony at Tier 0 Puts Real Data into Global Scope
- Physicist Tier 2 Runs Skim on One of Six Copies of AOD
- Somewhat Formal Use Cases
 DBS Requirements
DBS Requirements
Description of CSA06
We will start with use cases for CSA06. The description on the CERN CSA06 wiki is given in terms of dataflow, and a diagram of that dataflow is as follows. There is more information about CSA06 in Stefano Belforte's talk from CPT Week. (Look for “Computing View of CSA06.”)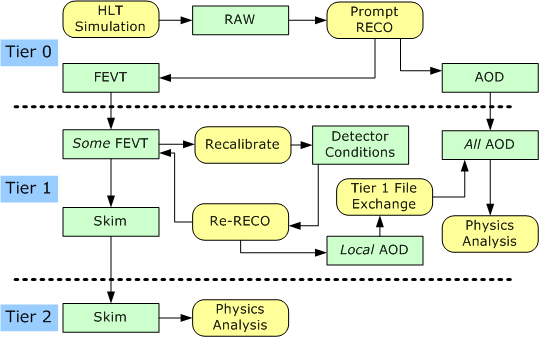 Corrections: AOD will be analyzed at Tier 2. Plus, there is a skim from AOD to Tier 2 analysis. There is also an application performing skims, so it should be a yellow block.
We expect reconstruction to produce FEVT and AOD datasets directly. The CERN wiki describes a calibration step, which might seem like it would occur at Tier 0, but the CPT Week presentation makes it more clear that CSA06 involves recalibration at Tier 1 of about five percent of the incoming FEVT. Because the AOD produced by re-reconstruction at Tier 1 must be distributed to all Tier 1 facilities, there is a step in the diagram representing the work of Phedex to transfer AOD. File transfer is also implied where arrows cross from one compute tier to the next.
The data flow diagram is implicitly in the passive voice because it does not specify which actors initiate transformations. If, instead, we ask who are the actors and goals, the Tier 1 analysis branch of that dataflow might look as follows.
Corrections: AOD will be analyzed at Tier 2. Plus, there is a skim from AOD to Tier 2 analysis. There is also an application performing skims, so it should be a yellow block.
We expect reconstruction to produce FEVT and AOD datasets directly. The CERN wiki describes a calibration step, which might seem like it would occur at Tier 0, but the CPT Week presentation makes it more clear that CSA06 involves recalibration at Tier 1 of about five percent of the incoming FEVT. Because the AOD produced by re-reconstruction at Tier 1 must be distributed to all Tier 1 facilities, there is a step in the diagram representing the work of Phedex to transfer AOD. File transfer is also implied where arrows cross from one compute tier to the next.
The data flow diagram is implicitly in the passive voice because it does not specify which actors initiate transformations. If, instead, we ask who are the actors and goals, the Tier 1 analysis branch of that dataflow might look as follows.
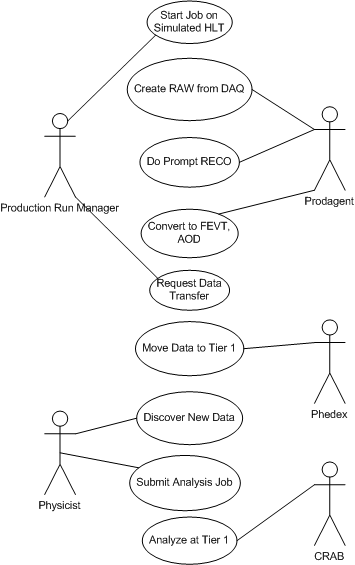 Note that the goals in CSA06 do not depend on provenance information. In order for Prodagent to identify its input data, it need know only that the data is from the RAW tier. In order for the Physicist to identify input data, he need know only that there is new data at Tier 1. Because there are few types of files to distinguish and no questions about the kind of processing done by Physicists, there are no queries of provenance information.
Note that the goals in CSA06 do not depend on provenance information. In order for Prodagent to identify its input data, it need know only that the data is from the RAW tier. In order for the Physicist to identify input data, he need know only that there is new data at Tier 1. Because there are few types of files to distinguish and no questions about the kind of processing done by Physicists, there are no queries of provenance information.
Actor-Goal List
We make an actor-goal list to use as a directory of relevant use cases. In formal use cases following, those that are well understood and less interesting will be omitted. For a discussion of terms, see the glossary. The actors are also identified in another topic.| Actor | Goal | Description |
|---|---|---|
| Production Manager | Create Simulated HLT RAW Data | The simulated HLT data is generic Monte Carlo. The Production Manager creates this by submitting a job to Prodagent. |
| Use Simulated RAW Data to Generate Reconstruction Data | CMS central facilities provide templates for simulation configuration and reconstruction configuration. They provide previously-calculated Monte Carlo simulation of a general sort. Prodagent handles this request by doing calculations on the server farm at CERN. There are two types of resulting files, full event (FEVT) containing RAW and RECO, and analysis-oriented dataset (AOD) containing a known subset of FEVT. The global DBS tracks the existence of the resulting data files. | |
| Recalibrate Reconstruction at Tier 1 | When FEVT data arrives Tier 1 Production Manager initiates recalibration of RECO data. This manager submits an analysis job at Tier 1 to CRAB. CRAB runs the job to produce improved detector conditions and re-run the reconstruction step (re-reco). CRAB uses a local DBS to track files during this process but the global DBS registers the revised FEVT and AOD data produced. Phedex polls the global DBS to discover the new data and transfer the AOD among sites so that every Tier 1 has a complete copy of revised AOD. | |
| Prodagent | Execute a Monte Carlo Run | Prodagent must complete an analysis job at a local compute cluster. |
| Physicist | Analyze AOD Dataset | Once a dataset arrives, a Physicist submits a job to CRAB to analyze AOD data. CRAB uses BOSS to analyze that data on the GRID. The global DBS registers the existence of the resulting USER dataset. |
| Skim FEVT Data | Once an FEVT dataset arrives, a Physicist submits a job to CRAB to skim the data. CRAB analyzes that data on the GRID. The global DBS registers the existence of the skim. Phedex transfers that skim to a Tier 2 site according to a subscription. | |
| Analyze Skim Data | Once an FEVT skim arrives, a Physicist submits a job to CRAB to analyze the data. CRAB analyzes that data on the GRID. The global DBS registers the existence of the resulting USER dataset. | |
| CRAB | Execute Monte Carlo Analysis | CRAB must ensure completion of an analysis job on the Grid |
| Phedex | Transfer Data As It is Produced | Tier 1 sites subscribe to FEVT and AOD data files produced by Tier 0. Phedex transfers those data files as they appear in the global DBS. The users check a log file to see the transfer status and eventual completion. |
Usage Narratives
Lothar talked about these usage narratives. The rest of the document may not yet match with them. These are more precise.Physicist Tier 2 Creates Skim of Re-RECO at Tier 1
Physicist polls list of available datasets for those produces by CSA06. He sees a job which he identifies as a skim by its name. Someone tells this physicist what Tier 1 has the data. The tool shows him the dataset identifier. He puts that identifier into a Prodagent job, along with the name of the Tier 1 on which to do processing.Physicist Tier 2 Discovers Tier 1 Data Available for Processing
Physicist polls a list of available datasets for datasets produced by CSA06. The physicist recognizes Re-RECO data because of the dataset name. The program (or web page) provides a dataset identifier.Physicist Tier 2 runs analysis job
Physicist asks CRAB to run an analysis job.Alignment Person Recalibrates using Z to mu-mu to produce a new version of alignment
Physicist polls a tool which shows a list of available datasets. He identifies CSA06 jobs by name. [Should be done at CAF, but not for CSA06.] He submits the alignment job to CRAB or Prodagent, which returns a new version of the alignment. Alignment person puts this alignment into alignment database.Production Manager Tier 2 Re-runs RECO analysis
Alignment person tells production manager about newly-available calibration. Production manager specifies new alignment in Prodagent or CRAB configuration file. Production Manager specifies a subset of the RAW dataset and submits it to run. Prodagent puts result into global DBS. (It could be a job robot that runs this instead of Prodagent or CRAB. How do you insert new detector conditions? Do you need a new version of the software or configuration.)Production Manager Watches CSA06 Progress
Production Manager wants to see what data exists and what file blocks are transfered. They open a web page tailored to CSA06. It queries the DBS for file existence and PhEDEx for file transfer rate. (Can PhEDEx tell you this? Would something else do it, like the DLS?)Production Manager Creates Real HLT Data from MC Data
Production Manager runs the HLT on a large dataset of MC Data. Production Manager uses Y to put that data into the DBS. Only five million events go through the HLT from all of the MC data, and DBS tracks these.Tony at Tier 0 Puts Real Data into Global Scope
He creates data with a set of scripts. He asks X to make file blocks from that data. He asks Y to put that data into the DBS.Physicist Tier 2 Runs Skim on One of Six Copies of AOD
Physicist sees in exploration tool that AOD is available at Tier 1 and can tell that this is AOD from Re-RECO. Physicist asks X where this data is stored. Physicist puts into the CRAB configuration the name of the dataset and where to do the computation. CRAB puts the resulting file into the DBS.Somewhat Formal Use Cases
Document Conventions
The scope identified in the following is design scope. It is the boundary of what we are designing in this use case. Typical design scopes would be Enterprise, System, and Subsystem. Our design scopes correspond to this chart. White boxes mean that the use case discusses internal behavior in the design scope, while black box use cases restrict themselves to system behavior.| Design Scope | Icon | Examples |
|---|---|---|
| CMS Data Management System |   |
Physicist finds file using CMS DMS |
| The individual application |   |
Prodagent or Phedex |
| The service system |   |
DBS or DLS |
| Goal Level | Icon | Example |
|---|---|---|
| Summary Level |  |
This is larger context for user goals. “Physicist searches for Higgs.” |
| User Goal |  |
Something you can sit down and do, such as running a job. |
| Subfunction |  |
This is a step in a user goal. “CRAB supplies GRID parameters to BOSS.” |
Generate Generic Monte Carlo
| Name: | 1. Generate Generic Monte Carlo |
| Actors: | Production manager, Prodagent |
| Goal Level: | Summary Level |
| Scope: | Application Scope |
| Description: | CMS central facilities provide templates for simulation configuration and reconstruction configuration. They provide previously-calculated Monte Carlo simulation of a general sort. Prodagent handles this request by doing calculations on the server farm at CERN. There are two types of resulting files, full event (FEVT) containing RAW and RECO, and analysis-oriented dataset (AOD) containing a known subset of FEVT. The global DBS tracks the existence of the resulting data files. |
| Revision: | Filled |
| Trigger: | CMS Central provides templates for simulation configuration and reconstruction configuration and requests output of a certain luminosity. |
| Primary Scenario: |
|
| Exceptions: |
3a. Computational resources fail to return all results.
3a1. Prodagent registers all completed results in DBS.
3a2. Prodagent reports missing results.
3a2. Production manager resubmits remaining parts of job.
|
| Alternate Scenario: | The input dataset could be simulated HLT trigger data so that prodagent processes RAW data instead of making Monte Carlo. |
Execute a Tier 0 Cluster Job
| Name: | 2. Execute a Tier 0 Cluster Job |
| Actors: | Prodagent, global DBS, local DBS, global DLS |
| Goal Level: | User goal |
| Scope: | Service scope |
| Description: | Prodagent receives configuration files describing a Monte Carlo job. It examines the input dataset and figures out what resources to use. It then runs the job and gathers results. |
| Revision: | Filled |
| Trigger: | Production manager submits a job, including a description of computational resources, simulation and reconstruction configuration templates, and what dataset to analyze, specified by a unique dataset name and set of event collections within that dataset. |
| Primary Scenario: |
|
| Exceptions: |
Physics Analysis of Monte Carlo
| Name: | 3. Physics Analysis of Monte Carlo |
| Actors: | Physicist, CRAB |
| Goal Level: | Summary level |
| Scope: | Application scope |
| Description: | This describes how a Physicist uses CRAB to Monte Carlo or real data. |
| Revision: | Filled |
| Trigger: | Physicist sees that generic Monte Carlo is ready to analyze. |
| Precondition: | Monte Carlo data exists in the data tier and physicist has access to the data. |
| Primary Scenario: |
|
| Alternate Scenarios: | Physicist may look in Dashboard or another application to see job completion. |
Execute a Physics Analysis on Grid
| Name: | 4. Execute a Physics Analysis on Grid |
| Actors: | CRAB, global DBS, local DBS, BOSS, global DLS, local DLS |
| Goal Level: | User goal |
| Scope: | Service scope |
| Description: | Physicist gives CRAB configuration files describing a Monte Carlo job. It examines the input dataset and figures out what resources to use. It then runs the job and gathers results. |
| Revision: | Filled |
| Trigger: | Physicist specifies a unique dataset with event ranges, an analysis workflow with parameters for each step, and which resources to use for processing. |
| Primary Scenario: |
|
| Exceptions: |
Examine Data Coming From Tier 0
| Name: | 5. Examine Data Coming From Tier 0 |
| Actors: | Physicist, Data Explorer, Local DBS |
| Goal Level: | Subfunction |
| Scope: | Application scope |
| Description: | While Tier 0 processes data, it streams AOD and FEVT from the prompt reconstruction to Tier 1. At Tier 1, physicists are waiting to analyze that data. Their goal is to identify data relevant to their analysis so that they can process it. |
| Revision: | Filled |
| Trigger: | Data processing starts, and the Physicist wants to start analysis. |
| Primary Scenario: |
|
| Alternate Scenario: |
3a. Local DBS provides timestamps for every file block in a dataset because Phedex did not transfer a whole dataset.
|
| Exceptions: |
Transfer File Blocks from Tier 0 to Tier 1
| Name: | 6. Transfer File Blocks from Tier 0 to Tier 1 |
| Actors: | Phedex, Global DBS, Global DLS, Local DBS, Local DLS |
| Goal Level: | User goal |
| Scope: | Service scope |
| Description: | The Tier 0 facility analyzes RAW data to product RECO, FEVT, and AOD data. The Tier 0 Production Manager is then responsible for transfering subsets of that data to Tier 1. It specifies datasets to Phedex, possibly before the datasets are closed, meaning that the distributed computing jobs which calculate those results have returned only part of the data. Phedex then transfers file blocks from those datasets to Tier 1, properly requesting that the Tier 1 Local DBS and Local DLS record the transfer. |
| Revision: | Facade |
| Trigger: | Production manager asks to transfer a partial or complete dataset. |
| Primary Scenario: |
|
| Exceptions: |
- Set USERSTYLEURL = https://wiki.classe.cornell.edu/pub/HEP/SWIG/DbsUseCases/UseCases.css
Edit | Attach | Print version | History: r7 < r6 < r5 < r4 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r6 - 22 Jul 2006, AndrewDolgert
Ideas, requests, problems regarding CLASSE Wiki? Send feedback